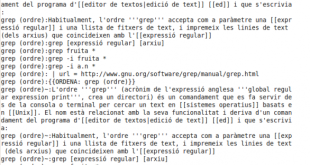
GREP, which stands for global regular expression print, is a sophisticated Linux/Unix tool that can serve many purposes, but one useful purpose on a dedicated server is its ability to search files and directories. With grep you can search within multiple files with relative ease. You can also parse printed …
July, 2010
-
22 July
Easily Repeat Root Commands with History
Previously, I mentioned some of the benefits of using the “history” command to display any or all of your previous commands. On dedicated servers, whether Linux or Unix, that use “sudo” rather than “su” to become root, it can be aggravating when you type a long command string only to …
-
22 July
Rsync Incremental Backups
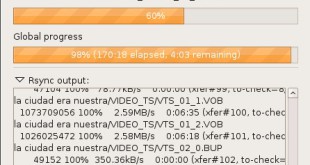
Question: How can I easily perform incremental backups on my dedicated server? Answer: There are few tasks more important than backing up your server. Because of the nature of computers and especially the nature of the Internet, you are bound to have problems. They may or may not cause data …
June, 2010
-
25 June
How To Create Multiple New Users
In Linux, the most common method used to create new users is to use the “adduser” command. This is fine when you need to add one or even a few users, but if you need to add numerous (i.e. 50, 100, or even 500), typing in the adduser command repeatedly …
-
24 June
Completely Delete Files with Shred
On a Linux dedicated server, the normal method for deleting files is to use the “rm” command. This removes the file from the current filesystem, but what many do not know is that those removed files are usually recoverable. As such, rm is more like putting something in the trash …
-
23 June
Quick and easy sudo trick for servers
Question: I just typed a really long complicated command line string on my server, but I forgot to type “sudo” at the beginning. Is there a quick way to enter it again? Answer: The history feature in Linux and Unix-like operating systems is truly a beautiful thing. With it, you …
-
21 June
How to Login as a Different User in Linux
Sometimes when I am working on a project and come across a new powerful Linux command, I need to test it. With a live dedicated server, that can be a recipe for disaster. Rather than taking such a risk with your websites and possibly the websites of customers (if you …
-
21 June
Removing Files on a Linux Server
An important part of file management is the removing of files that are no longer needed. Files, by their very nature, take up space, and something that is not needed should not take up space on a server, where space is money. The “rm” Linux command handles basic removal of …
-
17 June
Schedule Tasks on a Windows Server
There are two ways to schedule a task on a Windows server: graphical (from the system tools menu) or from the command line. Graphical 1. If you have direct access to the system tools menu, click the “start” button and then go to Programs > Accessories > System Tools > …
May, 2010
-
31 May
Using the Stat Command to Display Metadata
Linux servers provide system administrators with a great deal of flexibility and information about the inner workings of the system. If you ever want to know about every minute detail of your hardware, Linux can do that. The same is also true of hardware. For general files, the “stat” command …